Threes! AI — A Simple Distribution Method
The expectimax algorithm used by my AI for Threes! is fairly easy to parallelize, because the branches of the game tree can be surveyed in parallel. While developing the AI, I used the std::async function in C++ so that each node (up to a certain depth I defined) would run the expectimax algorithm on all of its child nodes in parallel. For production however, I wanted to run the AI on a small cluster of Raspberry Pis I had available, as they are fairly low power and, more importantly, they run silently.
In order to distribute the work amongst the Pis, I decided I would have one “master” computer that keeps track of the game state, decides what moves to make, and makes the moves. When deciding what the next move should be, this master computer then can use the help of the “worker” computers1. This worked better than just having each computer act as a worker, distributing work to its fellow workers. In this case, as you looked more moves in advance, each worker ended up spending a lot of time trying to find workers to distribute work to, which resulted in a lot of unnecessary holdup.
For communication between the computers, I chose to use simple TCP sockets. As my needs were quite simple, I decided to interface directly with the C APIs rather than finding a C++ socket library.
Here is a basic overview of what the master computer does when deciding what the next move should be:
-
Find the depth (number of moves ahead) which the AI will look. This is done by the
dynamic_depthfunction, which takes into account parameters like how far into the game the current move is and how many empty tiles there are on the board. -
Call the expectimax function, which traverses the game tree on the master computer until the parallelization depth is reached. The parallelization depth for each move is a constant number of levels above the leaf nodes.
-
When the parallelization depth is reached, iterate through each of the parallelized node’s children, and ask an available worker to find the score of this child. Wait for the results from the workers.
-
Use the results from the workers to find the score of the parallelized node. The score of the parallelized node is then used by the parent node to find the score of the parent, then the parent of the parent node to find the grandparent node’s score, and so on until the root node is reached.
-
When the root node is reached, choose the move corresponding to the highest scoring branch as the next move.
It’s step 3 in which the distribution occurs. This occurs by a short sequence of messages between the master and workers. Each message is prefixed by 4 characters which signify the length of the body of the message2, so the receiving computer knows how many characters it should listen for.
Firstly, the master sends each worker node the “READY” message:
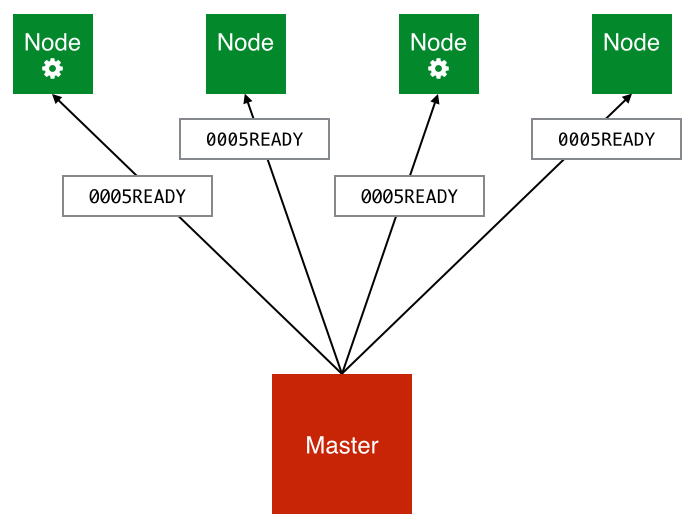
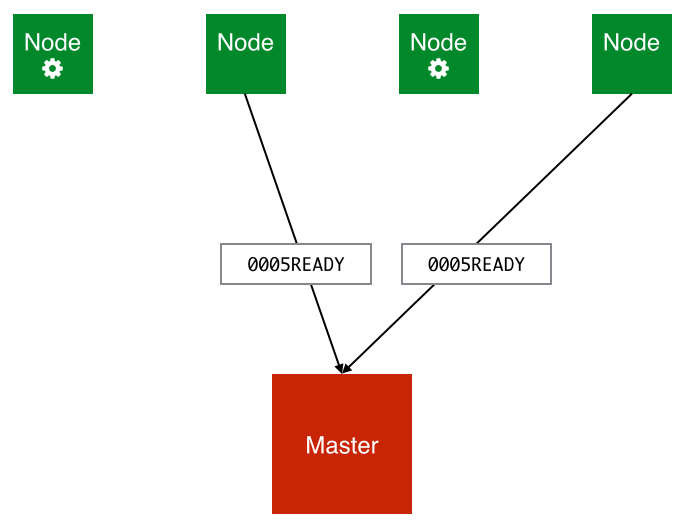
Workers that are currently not processing a job listen out for this message, and will respond with the “READY” message to indicate that they are ready to accept work from the master:
The master then serialises the board data along with a few other parameters and sends this data to the first-responding worker:
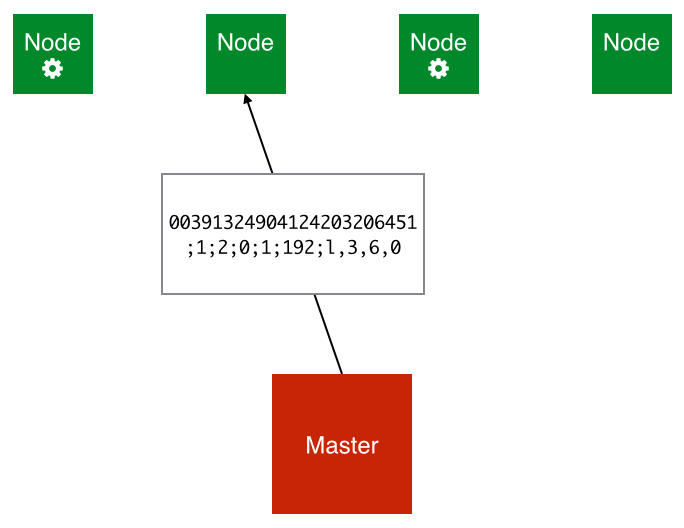
This message is structured as follows:
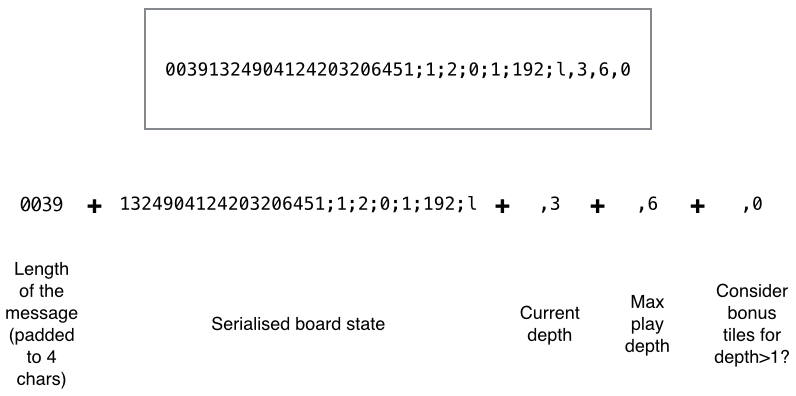
The worker now decodes the message, creates the board object, and surveys the remainder of the branch locally with the expectimax algorithm. It then sends the score of the parallelized node to the master (in this case 2637.436035) and closes the connection:
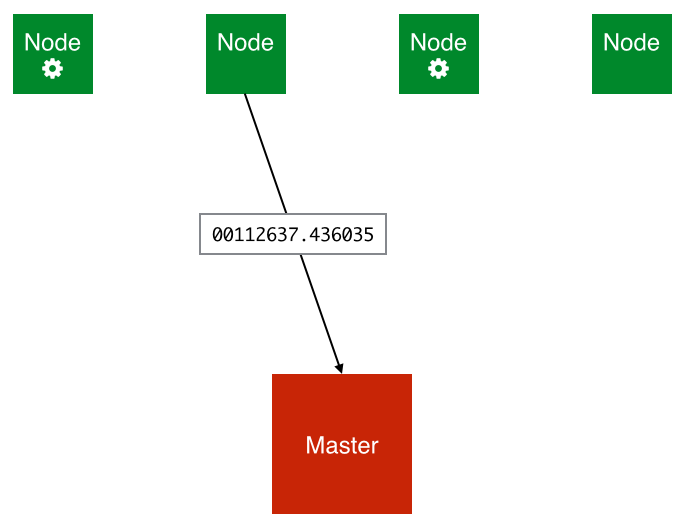
-
Technically, the master computer is also a worker: due to the low resource usage of the master process, it makes sense to run a worker process on the same computer to utilise as much of the cluster’s computing power as possible. ↩
-
A higher base could have been used to represent this length in order to code for longer message bodies, but this is unnecessary here as the message body length should never exceed 9999 characters. ↩